PHD PROPOSAL: DEVELOPMENT OF AN INTELLIGENT ANALYTICS-BASED MODEL FOR ANALYZING CONSUMER BEHAVIOUR TO PREDICT THEIR ONLINE PURCHASE INTENTION
http://ilokabenneth.blogspot.com/2019/08/phd-proposal-development-of-intelligent.html
Author: Iloka Benneth Chiemelie
Published: 4th August 2019
Published: 4th August 2019
Introduction
Based on some estimated, it is believed that
Walmart gathered about 2.5 petabytes (1 petabyte = 1,000,000 gigabytes) of
information per hour with these information related to consumer behaviour,
transactions, devices used by the consumers and their locations (McAfee et al.,
2012). It is also estimated by a Gartner IT analyst that there will be about 20
Billion (13.5 Billion in the consumer sector) that will be connected in the
“Internet of Things”. If such connections are made, one can only imagine the
volume of data that these devices will generate (Gartner, 2015). Such
imagination can be further extended to the day that retailing data (both online
and offline) can be used to provide a complete view of the consumer buying
behaviour, and such can even be made better if these data are linked to all
levels of the individual consumer in order to actually create “true” lifetime
value calculations for the individual customers (Gupta et al., 2006; Venkatesan
and Kumar, 2004). Lets further imagine the data where the data that were
believed to exit in online retailing, for instance, the consumer path data (Hui,
Fader, Bradlow 2009), are made available inside the store due to RFID and other
technologies that are based on GPS-tracking. This can even be made further
interesting if one is to visualize a day in which the online and offline
integration are being run in such a way that they offer exogenous variations
that would make it possible to have casual inference on retailing/marketing
topics like the efficacy of advertising, email, coupons, and so on (Anderson
and Simester, 2003). There could also be a day when it won’t just be possible
to gather eye-tracking data from Tobii-enhanced monitors in laboratory, but
such data becomes possible to gather in the field because of retinal scanning
devices that become a common place among marketers (Lans, Pieters, and Wedel et
al, 2008; Chandon et al, 2008).
Although all these sources might sound
futuristic, the fact is that they all exist at present (although not
ubiquitous, but at least albeit) and it is expected that they will soon become
part of the information being utilized by marketing scientists for
understanding customer-level information and optimizing firm-level objectives.
It can be heuristically and simply put that, these sources of data will be
creating more ‘columns’ in databases (and this columns will continue to
increase) up to the extent that they provide increased ability of businesses to
predict the behaviour of consumers and the influence that marketing has on such
behaviour. If that becomes possible, add it to the technology (in the form of
IP address tracking, registered-user-log-in, cookie tracking, loyalty card
usage, and a host of others) which makes it possible for companies to gather
information millions of customers, at any given time, which is linked to each
and every transaction that these consumers make, linked to each and every touch
point in firm-level analysis, and also linked to different platforms used for
distributing goods and services, and one will see that what becomes of it is
the big data that is frequently featured in the press today.
Although the lure (and lore) that comes with
big data makes it tempting, the position of this paper is that the revolution
of big data (McAfee et al. 2012) is actually a “better data” revolution, and
this is even more so in the context of retailing. Thus, the intention of this
research paper is to offer vivid description on the latest forms of data (which
is the “new columns”) that are now obtainable in the retailing industry; the
importance of experimentation and exogenous variations (“better columns”); in
order to offer description on why machine learning and data mining
(notwithstanding the pros that come with them) would never obviate the need for
economic/marketing theory (which is “which part of the data to look into”); describing
the statistical methods and managerial knowledge that would be used to create
smart data compressions (“the columns” and their summaries) that would make it
possible for the data to be aggregated by researchers; how the data can be
better feed into predictive models (for instance, choice models, diffusions,
CLV etc.); and finally, how likely the firms are to utilize the data for
decision making. This model, which includes both the bucket and order of data,
is a visual representation of the definition of business analytics offered by
INFORMS (www.informs.org) to include: descriptive analytics, predictive
analytics and prescriptive analytics.
Problem
statement
An excellent analytics on the present, past
and future of marketing analytics was offered by Li and Kannan (2016) and
Little and Rubin (2014). Discussion in this work feature how marketing
analytics will be used to shape future decisions making by managers when it
comes to allocation of marketing mix, customer relationship management,
customer privacy, personalization and security issues. Although this
discussions support the idea of business analytics being important, just like
most of the researchers in this area, efforts were not made in terms of
developing models for how the analytics can be undertaken and this is the gap
that the present study aims to fill. Mainly,
the focus of application of Big Data in marketing has been on: (a) assessing
the preference of consumers (e.g., Jacobs et al., 2016), (b) predicting what
consumers are most likely to purchase (e.g., Ghose et al., 2012; Lu et al.,
2016; Linden et al., 2003), (c) enhancing targeted advertising (e.g., Hauser et
al., 2009; Trusov et al., 2016), (d) understanding consumers’ perception about
brands (e.g., Culotta and Cutler, 2016; Tirunillai and Tellis, 2014), and (e),
describing the competitive sphere of a market or product (e.g., Netzer et al.
2012). This research basically aims to develop an
intelligent analytics-based model that can be used to analyze consumer
behaviour in order to predict their online purchase intention, thereby, putting
the existing theories in this context into practice.
Research
objectives
In view of the discussion above, the
objectives of this research are:
1.
To
present a comprehensive analysis of the past, present and future of big data
analytics.
2.
To
discuss the impact of data analytics on effective and efficient corporate-level
decision making.
3.
To
develop an intelligent analytics-based model that can be used for analyzing
consumer behaviour and predicting their purchase intention in the online
setting.
Research
framework
Figure 1: research framework
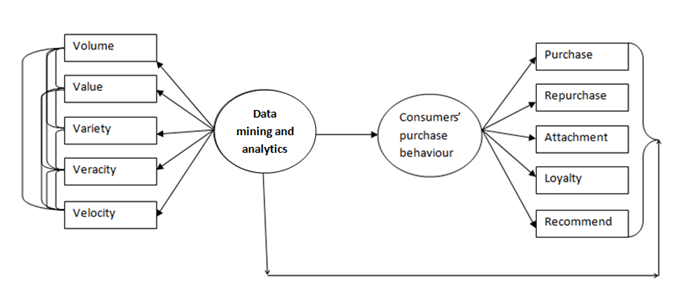
From the figure (1) above, there are two
variables in this research. The independent variable is data mining and analytics, while the dependent variable is consumers’ purchasing behaviour. Basically,
this research is exploratory and it will be designed to analyze the
cause-and-effect relationship between the independent and dependent variables.
In the case of such analysis, discussions on the independent variable will look
at data: volume, value, variety, veracity, and velocity; while discussion on
the dependent variable will consider how such can be used to predict intention
of online consumers in relation to: purchase, repurchase, attachment, loyalty,
and recommendation.
Methodology
As stated earlier, this will be an
exploratory research. In the course of attaining the objectives of this paper,
two steps will be undertaken. The first step will be secondary data analysis.
In this case, the research will source and analyze existing studies in the
context of this research in order to provide vivid understanding of the
variables in this study. This will be followed by the second step, which will
be development and demonstration of the intelligent analytics-based model for
analyzing consumer behaviour and predicting purchase intention of online
customers. In this section, the model development will be based on information
from the secondary data, while the testing of developed model will be done with
PYTHON Programming. For the testing stage, existing consumer data will be run
in the programming software and path analysis conducted to demonstrate how data
analytics can be used to predict the future purchase intention of consumers
based on analysis of their past and present behaviour.
References
Anderson,
E., T. and Simester, D. (2003) Effects of $9 Price Endings on Retail Sales:
Evidence from Field Experiments. Quantitative Marketing and Economics. 1(1):
93-110.
Culotta,
A. and Cutler, J. (2016). Mining brand perceptions from twitter social networks.
Marketing Science, 35, pp. 43-362.
Ghose,
A., Ipeirotis, P., G. and Li, B. (2012). Designing ranking systems for hotels
on travel search engines by mining user-generated and crowdsourced content.
Marketing Science, 31, pp. 493-520.
Gupta,
S., Hanssens, D., Hardie, B., Kahn, W., Kumar, V., Lin, N., Ravishanker, N. and
Sriram, S. (2006) "Modelling customer lifetime value." Journal of
service research, 9(2), pp. 139-155.
Hauser,
J., R., Urban, G., L. and Liberali, G. (2009). Braun M: Website morphing.
Marketing Science, 28, pp. 202-223.
Hui,
S., K., Peter, S., F. and Bradlow, E., T. (2009) "Path data in marketing:
An integrative framework and prospectus for model building." Marketing
Science, 28(2), pp. 320-335.
Jacobs,
B., J., D., Donkers, B. and Fok, D. (2016). Model-based purchase predictions
for large assortments. Marketing Science, 35, pp. 389-404.
Li, H.
and Kannan, P., K. (2014) "Attributing conversions in a multichannel
online marketing environment: An empirical model and a field experiment."
Journal of Marketing Research, 51(1), pp. 40-56.
Linden,
G., Smith, B. and York, J. (2002). Amazon.com recommendations: item-to-item
collaborative filtering. IEEE, 7, pp. 76-80.
Little,
R. J., & Rubin, D. B. (2014). Statistical analysis with missing data. John
Wiley & Sons.
Lu, S.,
Xiao, L. and Ding, M. (2016). A video-based automated recommender (VAR) system
for garments. Marketing Science, 35, pp. 484-510.
McAfee,
A., Brynjolfsson, E., Davenport, T., H., Patil, D., J. and Barton, D. (2012)
"Big data: The management revolution,” Harvard Bus Rev, 90 (10), pp.
61-67.
Netzer,
O., Feldman, R., Goldenberg, J. and Fresko, M. (2012). Mine your own business:
market-structure surveillance through text mining. Marketing Science, 31, pp.
521-543.
Tirunillai,
S. and Tellis, G., J. (2014). Mining marketing meaning from online chatter:
strategic brand analysis of big data using latent dirichlet allocation. Journal
of Marketing Research, 51, pp. 463-479.
Trusov,
M., Ma, L. and Jamal, Z. (2016).Crumbs of the cookie: user profiling in
customer-base analysis and behavioral targeting. Marketing Science, 35, pp.
405-426.
Van der
Lans, R., Pieters, R. and Wedel, M. (2008) "Research Note-Competitive
Brand Salience." Marketing Science, 27(5), pp. 922-931.
Venkatesan,
R. and Kumar, V. (2004) A Customer Lifetime Value Framework for Customer
Selection and Resource Allocation Strategy. Journal of Marketing: October 2004,
Vol. 68, No. 4, pp. 106-125.





